各有关单位:
为进一步规范肿瘤相关突变基因检测产品的注册申报和技术审评,提高审评效率,统一审评尺度,根据原国家食品药品监督管理总局2018年度医疗器械注册技术指导原则制修订计划的有关要求,我中心组织起草了《肿瘤相关突变基因检测试剂(高通量测序法)性能评价通用技术审查指导原则》。经文献汇集、企业调研、专题研究和专家讨论,形成了征求意见稿。
为使该指导原则更具有科学合理性及实际可操作性,即日起在我中心网上公开征求意见,衷心希望相关领域的专家、学者、管理者及从业人员提出意见或建议,推动指导原则的丰富和完善。
请将意见或建议以电子邮件的形式于2018年9月15日前反馈我中心。
联系人:关红、吴传松
电话:010-86452594;010-86452591
电子邮箱:guanhong@cmde.org.cn wuchuansong@cmde.org.cn
附件:1.肿瘤相关突变基因检测试剂(高通量测序法)性能评价通用技术审查指导原则(征求意见稿)(下载)
2.反馈意见表(下载)
国家食品药品监督管理总局
医疗器械技术审评中心
2018年8月14日
肿瘤相关突变基因检测试剂(高通量测序法)性能评价通用技术审查指导原则
一、前言
本指导原则旨在指导注册申请人对肿瘤相关基因检测试剂分析性能评价注册申报资料的准备及撰写,同时也为技术审评部门对注册申报资料的技术审评提供参考。
本指导原则是针对肿瘤相关基因检测试剂分析性能评价的一般要求,申请人应依据产品的具体特性确定其中内容是否适用,若不适用,需具体阐述理由及相应的科学依据,并依据产品的具体特性对注册申报资料的内容进行充实和细化。
本指导原则是对申请人和审查人员的指导性文件,但不包括注册审批所涉及的行政事项,亦不作为法规强制执行,如果有能够满足相关法规要求的其他方法,也可以采用,但需要详细阐明理由,并对其科学合理性进行验证,提供详细的研究资料和验证资料,相关人员应在遵循相关法规的前提下使用本指导原则。
本指导原则是在现行法规和标准体系以及当前认知水平下制定的,随着法规和标准的不断完善,以及科学技术的不断发展,本指导原则相关内容也将适时进行调整。
二、适用范围
本指导原则所述肿瘤相关基因检测试剂分析性能评价主要是指基于高通量测序(high-throughput sequencing)即下一代测序(next generation sequencing, NGS),又称为大规模平行测序(massively parallel sequencing, MPS),体外检测人体组织中肿瘤细胞中肿瘤相关基因变异。用于检测体细胞突变的NGS正在广泛用于肿瘤诊疗相关的分子检测,包括对特定基因的DNA/RNA进行测序,以寻找与肿瘤临床诊疗相关的突变基因的改变。肿瘤基因突变类型包括点突变、插入、缺失、基因重排、拷贝数异常等广义的基因突变。
基于NGS测序原理的IVD检测可能包括以下步骤:样本收集,处理和保存、DNA提取、DNA处理、文库制备、测序和碱基识别、序列比对/映射、变异识别和过滤、变异注释和解读以及检测报告的生成。同时,某些产品还可能会包括软件部分,但上述相关步骤并不一定被全部包括,应根据产品的具体设计流程来进行判断。对于每个检测步骤,申请人需要结合产品设计和临床意义来建立特定的可接受的质量评价指标和合格判断标准。此外,为满足产品特定预期用途,申请人需通过科学和适当的检测性能研究来确定适用的试剂,消耗品,仪器和软件。基于上述考虑因素,NGS检测产品的设计和工作流程中的任何差异均可能导致结果的不同,因此申请人需要清楚地描述相关检测性能指标。
分析性能评价的初衷在于提出产品性能有效性、安全性相关问题的假设,然后通过研究进行确认。NGS在测序通量及发现未知基因变异方面具有优势,但是在NGS技术应用需求及使用中存在包括相关临床样本收集处理、NGS检测内容、测序流程、数据分析、结果报告、技术质量认证和验证等各方面的挑战。
本指导原则将重点关注实体瘤中检测具有临床意义的体细胞变异和确保高质量的测序结果。申请人应以患者的利益为中心,充分整合临床肿瘤学家对于精准诊治的观点,并充分考虑在我国推广应用的可操作性。申请人可采用多样化的靶向基因组合检测。由靶向基因组产生的信息可能会被用于诊断分类,指导治疗决策,和/或为特定肿瘤提供预后评价,不同产品包含的基因数量可能存在较大差异。
本指导原则适用于进行首次注册申报和相关许可事项变更的产品。本指导原则不适用于基于胚系来源检测,全外显子检测,肿瘤突变负荷(TMB)检测,非靶向测序,从头测序、微生物感染辅助诊断、游离DNA检测、直接面向消费者测序、胎儿检测、微生物基因组鉴定和药物耐药性检测、胚胎植入前检测、疾病风险(含遗传风险) 评估与预测、RNA直接测序、筛查、独立诊断目的、肿瘤基因组测序、健康个体测序检测。
三、NGS性能评价
(一)综述资料
综述资料主要包括产品预期用途、产品描述、有关生物安全性的说明、研究结果的总结评价以及同类产品上市情况介绍等内容。
作为IVD检测一般原则,申请人应首先定义申报产品的预期用途和检测性能,产品的预期用途将直接影响检测设计和检测性能以及测序和/或报告的基因类型。申请人需要前瞻性地确定应进行的研究指标(例如准确性)以及每种研究指标应该满足的标准。在设计和开发完成之后,验证研究其是否满足预定义的性能。如果检测不符合任何预定义的性能标准,则应该修改并重新验证。通过反复的设计,开发和验证,直到检测满足设定需求。在整个过程中,申请人需要记录所有研究方案,研究过程和结果,以及每项研究设计的理由。申请人应列出检测样本水平相关参数,建议以列表形式明确,详见附表1
申请人应提供整个检测流程SOP文件,对NGS技术检测全过程包括的样本收集处理、文库制备、测序、数据分析、结果报告等过程进行详细描述。生物信息学分析方面描述和记录数据处理和分析,包括变异识别,过滤和注释的所有过程。明确所有要使用的软件,包括来源(例如,内部开发的以及第三方的)以及任何修改。建议以列表形式描述所有需要的软件和/或数据库名称及其功能。
申请人在计划开发一个有针对性的基因检测试剂时,需确定其预期用途和待测基因数量,包括将要检测的样本类型、适用人群以及哪些类型的检测信息将被评估和报告。还应考虑影响检测的设计,验证和质量控制的其他因素。并在试剂组成说明书中应详细说明该产品包含的试剂组分及需要但未提供的试剂、设备及耗材。
(二)主要原材料的研究资料
NGS检测过程主要包括样本收集处理、文库制备、测序、数据分析、结果报告等。
1.样本收集处理(如适用)
样本收集处理过程是保证样本具有能如实反映患者体征的关键环节。申请人需提交涉及样本收集及处理相关试剂主要原材料信息,如样本的运输保存试剂、样本制备试剂、核酸提取试剂的主要组成成分等。
2. 文库制备及测序
测序文库及测序过程主要包含脱氧三磷酸核苷、接头序列、连接酶、聚合酶、逆转录酶、限制性内切酶、引物、探针、接头等;如为申请人自行研究主要原材料,申请人应对测序文库构建的实验过程予以详述;并提供对各主要原材料的功能性研究。并对制备完成的原料成品进行质量检验以确认其符合标准要求,整个生产工艺应稳定可控。如为申请人外购主要原材料,应详述每一原材料外购方来源,提交外购方出具的每种原材料性能指标及质量控制资料,并详述申请人对外购主要原材料的各指标质量要求以及确定该原材料作为本产品主要原材料的详细依据。核酸类检测试剂的包装材料和耗材应无脱氧核糖核酸酶(DNase)和核糖核酸酶(RNase)污染。
3.生物信息分析及数据库要求
NGS的数据分析流程或生物信息学流程一般可以分为四个主要操作:碱基识别,序列比对,变异识别和变异注释。明确参考序列类型,辅助测序比对拼接和测序结果确认。不同突变类型可能需要开发不同的变异/突变检测算法。其次,因根据产品设计类型提供软件工具的范围和所需的验证类型。建议申请人提交数据库(参考序列)的溯源信息、数据库类型、完整性、实时性、维护以及升级方案以及分析软件的版本、算法、性能验证以及升级方案等资料。
4.内部参考品是保证产品性能稳定性以及检测值可溯源的重要构成之一。参考品研究应包括原料选择、制备过程、定值研究、评价指标、统计学分析等。申请人应对内部阳性/阴性参考品的来源、基因序列设置等信息进行精确的实验验证,并提供参考品溯源过程的测量程序或参考方法的相关信息及详细的验证资料。
具体要求如下:
4.1阳性参考品及阳性质控品:
4.1.1阳性参考品
理想状态下,阳性参考品应当包括对所申报产品每个基因型的质控样本。但考虑到基于NGS技术的可检测基因数量较多,申请人应结合产品预期用途、临床意义及基因类型等因素进行针对性和代表性的设计。
阳性参考品应包含所有需有明确药物治疗用途的基因类型,如对药物使用具有明确指导性的位点的参考品设置,需至少包括不同基因类型中代表性的基因类型,应采用临床样本或细胞系提取的DNA储备液作为原料。
对于具有显著临床意义或潜在临床意义的基因,因考虑代表性问题,明确具有临床诊断意义的基因类型及基因型中不同的变异类型,突变频率、变异类型的选取应具有代表性,包括不同外显子,不同基因变异突变等。如检测目标区较大(大于1M),需对检测区域整体和灵敏度进行质控(特别是针对SNV),可以采用混合的永生化正常人白细胞DNA储存液(HapMap细胞系)等。
不同突变/变异的变异丰度及突变频率,浓度范围设置应具有代表性并提供这样设定的依据。阳性参考品的突变形式及拷贝数需采用有效方法进行确认,并明确接受标准。申请人在设计阳性参考品时可一并考虑检测限参考品的设置及确认方式,并提供相关的依据。
4.1.2阳性质控品
模仿病人样本的目标核酸序列,并用于质控整个检测过程,包括核酸提取(如适用)、文库构建、测序和数据分析。目前阳性质控检测和分析过程应与临床样本方式一致。
4.2阴性参考品及阴性质控品
阴性参考品应为FFPE 正常样本的混合物,阴性质控品FFPE 正常样本的混合物或细胞系,应明确不含有目标区域肿瘤突变基因以及目标基因中的胚系突变基因。
4.3精密度参考品
精密度参考品设置要求可参考阳性/阴性参考品。
4.4 PCR 试剂无模板参考品(NTC)
申请人应建立NTC 对照Qubit 检测接受标准。监测检测过程中是否存在染污。
(三)主要生产工艺及反应体系的研究资料
NGS检测是一个复杂的工作流程,它由很多独立步骤组合而成。基于NGS的检测可能包括但不限于以下步骤:样本采集,处理和存储;DNA提取;DNA处理和文库制备;序列读取和碱基识别;序列比对,变异识别,变异注释和过滤,变异评估和注释,以及生成检测报告。一般而言,对于每个检测组成部分,申请人应建立其特定检测的指标和验收标准。必须对NGS每个操作流程的性能表现进行一个内部的验证。每步流程都需要分别优化到一个最佳经验值,以此来综合决定最佳的实验操作条件及各参数的设置。
1.应能对反应体系涉及到的基本内容,如临床样本用量、试剂用量、反应条件、质控体系设置等,提供确切的依据,配制工作液的各种原材料及其配比应符合要求。
2.主要生产工艺、反应原理介绍。逆转录过程(如涉及)及最佳反应体系的研究资料,包括酶浓度、引物/探针浓度、dNTP浓度、阳离子浓度等。确定的温度和时间的研究资料。
3.申报产品包含核酸分离/纯化试剂,应提交对核酸分离/纯化过程进行工艺优化的研究资料。如包括但不限于核酸体积、质量、浓度、纯度及完整性等。核酸浓度、纯度检测方法包括但不限于荧光法等;核酸完整性检测方法包括但不限于琼脂糖凝胶法、实时荧光定量PCR法等。
(四)分析性能评估资料
分析性能评估是反映产品主要原材料选择,生产工艺及反应体系等多方面因素设置是否合理的客观评价指标。检测试剂性能的研究方案应结合产品的反应原理,临床预期用途,使用条件等综合因素进行设计。性能研究应涵盖产品研制阶段对试剂盒进行的所有性能验证的研究资料,包括具体研究方法、内控标准、实验数据、统计分析等详细资料。
本部分内容将从NGS检验流程中的质量控制要求和主要性能指标两部分进行要求:
1.NGS检验流程
检测方法中,应明确所有检测要素(例如,仪器,软件,消耗品,试剂)和用于检测的实验室设备的检测要素。确定设计方案和标准并详细记录设计研究过程。对于基于NGS的检测的每个组成,应该确定规范并记录。记录每个检测组成对于关键因素(例如覆盖率,碱基质量)的局限性。确定并记录基因组的检测区域,包括基因和变异类型,如果关键的测序区域不符合最低性能要求(例如最小覆盖标准),则应修改检测并重新验证以达到最低性能要求。同时,应在产品说明书和/或标签中明确可能影响或限制产品检测性能情形。
1.1样本制备
申请人需考虑可接受检测的样本类型对检测结果的影响,例如所需采集设备的类型,样本的最小体积或数量,或采集和使用之间样本稳定性必须遵守的任何采集条件。每种样本类型及采集方式应建立相应的SOP,并验证对其整体检测性能的影响。
在NGS检测试剂的设计开发过程中,申请人应对配套使用的核酸提取、分离、纯化及富集试剂进行验证并提供验证方案的依据,建议包括但不限于核酸质量、浓度、纯度及完整性等。核酸浓度、纯度检测方法包括但不限于荧光法等;核酸完整性检测方法包括但不限于琼脂糖凝胶法、实时荧光定量PCR法等。应明确样品质量(包括但不限于核酸浓度、纯度及完整性)的最低要求并进行质量控制。如分离/纯化后的核酸储备液质量(如浓度范围)不符合要求,应重新取材或扩大样本量再进行核酸分离/纯化。
1.2测序文库制备
文库制备是产生特定大小范围的DNA或cDNA片段的过程。申请人应根据不同测序平台的性能特点,对核酸序列进行片段化处理,片段的长短应符合后续测序的要求,片段化方法包括但不限于超声法、酶切法等。申请人应制定核酸序列片段化操作流程及质量控制方案,对经过片段化的核酸短序列的浓度、纯度及片段分布等参数进行验证。
文库制备的关键步骤是在DNA片段的两端连接测序接头,接头序列是一段人为设计的序列,包含用于测序过程的多个目的的多个序列组分。如启动测序反应的通用测序引物序列,用于PCR扩增引物序列,锚定序列,索引(条形码)序列。如申请人采用自定义序列,应提供设计依据及研究资料。加接头可以是独立的步骤,也可以在靶向序列富集过程中添加。申请人使用条码或标签时,需充分验证并满足测序所需的质量要求,如测序深度、覆盖度等条件。同时,申请人应对潜在的问题进行充分研究,包括但不限于:条码检出率的均匀性、条码互换比率以及条码间相互污染或干扰等因素。申请人应报告有效的条码或标签数量,并对每个条码或标签的序列及其位置有详细、清晰的记录。
1.3测序及碱基读取
目前可用的测序平台具有不同的测序方法,包括联合探针锚定聚合测序法、合成测序和离子半导体测序,以及不同的检测方法。尽管技术性能相似,平台之间也存在差异,特别是不同的DNA输入量要求,不同的试剂成本,运行时间,读数长度和每个样本的成本。这些差异会影响仪器处理低质量样本的能力,检测插入/缺失的能力以及样本通量。
申请人应根据所选用的测序平台,选择合适的参数指标对测序质量进行监控,制定相应的管理制度及质量标准,并明确失控情况下的纠正措施。申请人应根据具体应用情况,如测序区域的大小及序列特征等因素确定测序所需要的覆盖度及深度。在测序过程中,申请人应建立标准操作流程及质量控制方案监控整个测序过程当中的测序质量。
申请人应根据具体的预期用途,制定产品的测序总体数据量、覆盖度(read数)和深度要求,并提供充分的理论依据及验证结果。申请人应描述清晰,例如,在确立测序深度时需要明确指出是平均测序深度还是最低测序深度;还需要说明测序数据类型,如原始测序数据(原始read数)、过滤之后的高质量测序数据、去除重复之后的数据计算测序深度。
碱基识别是指识别一段基因序列片段每一个位点的核苷酸的过程。不同测序平台具有不同的测序偏好性,可影响碱基读取过程中的错误类型与比率。应用软件可以消除或部分抵消测序偏好性的影响,提高碱基读取的准确性。碱基读取后,申请人应对每个碱基读取的质量进行评估。若碱基读取质量有通用标准,则应遵循并引用;若没有通用标准,可根据具体应用情况制定碱基读取质量评价标准及分析方法,并提供充分的理论依据及验证结果。
1.4生物信息学分析
申请人应对生物信息学分析流程有完整的记录,建立完善的生物信息学分析软件的版本控制方案。申请人应建立生物信息学分析标准操作流程及质量控制方案,保证测序数据的分析、解读及报告的准确性与严谨性。生物信息学分析流程应描述清晰,包括每一步骤使用软件的名称、版本、参数设置要求,包括但不限以下指标:说明检查每个读段和每个碱基的Q值,碱基的频率分布,读长分布及是否存在重复序列和人工序列的评价方法,以保证按照该流程生物信息学分析结果可复现。生物信息学分析应至少报告具有明确临床指导意义的结果。
生物信息学分析一般包括但不限于碱基识别,碱基对比,变异识别和变异注释。根据测序类型和检测报告的变异类型选择生物信息流程,并考虑变异识别和评估流程过程中的限制因素以及第三方生物信息学工具对整个生物信息流程的影响。
1.4.1数据追踪和记录:软件应自动对样本跟踪以及记录每个测序Run 相关多种数据信息(如:索引(条形码),测序run 记录,样本登记号,患者病例号,样本来源,样本类型,以及测试版本等)
在数据分析不同阶段进行样本状态跟踪;对指定样本进行反复分析跟踪;记录分析中使用的算法以及数据库版本信息;选择的流程输出的文件(如:FASTQ,BAM,VCF等)以及测序Run 相关统计参数(如,簇密度,簇通过过滤条件比例,未分配序列索引等)。
1.4.2碱基识别随着测序循环数的增加,测序数据质量可能因测序系统噪音等问题出现下降,申请人需提供碱基识别的软件资料,包括分析软件可以满足申报产品预期用途的研究资料,质量阈值设置依据。根据申报产品可检测的基因类型,申请人应确认软件工具的范围和所需的验证类型。并提供不同的计算方法研究资料。申请人应说明分析流程使用的软件类型。FASTQ 文件生成过程。明确去重质控参数,如每个碱基测序质量质控参数,序列内容,GC 含量以及序列长度分布,未匹配索引的相比对比例。
明确测序读数的基准质量得分(例如Q得分)的阈值。明确中等基准质量和基准百分比高于预定质量阈值的标准。明确修剪碱基百分比的阈值(如适用)。如采用其他方法,应提供研究资料及选择依据。
1.4.3基因组对比以及BAM 生成
申请人应提供适用于检测的过滤规则,明确过滤阈值及过滤目的和方式。例如,覆盖深度(DP)、突变序列数量(AD)频数均一化覆盖深度和变异频率(VF)、假的接头序列、去除PCR重复片段、消除低等位基因频率的变体、使用数据库来帮助注释和过滤的难以检测序列区域、验证特定的检测群体是否包含在数据集中,并记录数据库版本号。
申请人应提供参考序列的选择依据,本指导原则不适用于从头测序法,如为特殊序列,应提供采用该序列的依据并明确适用测序平台的关键序列信息。比对的序列被写入序列比对图(SAM)文件,接着转换成二进制比对图(BAM)格式。
1.4.4突变基因分析:分析流程识别不同突变类型,通过过滤去除低质量测序数据。
1.4.5突变注释:申请人应提供每个突变预测的功能性作用以及临床解释注释的形成过程及数据来源依据。
1.5 NGS数据的存储、传输与共享
用于储存原始和经过分析后的检测结果。建议申请人提交数据存储中心的安全性、稳定性、维护与升级方案以及异常情况处置方案等资料。
1.6 公共/内部数据库应用(如适用)
如申报产品的测序结果需要借助公共/内部数据库进行结果注释或报告解读,申请人需提供所使用的公共/内部数据库在产品检测中起到的作用说明,公共/内部数据库类型,功能介绍,标准操作流程及质量控制方案等。
2.主要性能指标
分析性能验证包括通过一组预定义性能评价方式,以证明性能是否足以满足其预期用途并符合预定义的性能标准。通常涉及是否符合统计学评价要求,或检测是否存在关于患者的疾病或其他病症信息的变异等。
2.1分析性能用样本设置要求
申请人应提供用于评估各项性能研究的标本数量和类型设定的依据。根据产品预期用途,样本研究应包括代表性变异和变异类型。研究应考虑与检测适应症相关的临床意义区域,跨不同基因组的变异、基因组难以测序或难以比对的区域,人工混合嵌合体以及任何其他变体类型,区域或区域上下限。例如:如果检测旨在用于检测和报告indel,则应包括以适当大小的基因片段包括变异的分布,插入和缺失。
应在研究中使用含有与检测适应症相关的临床相关变异的临床样本,并应选择适当的代表性以确保声称可通过检测和报告的临床相关序列变异和基因组情况。应尽可能使用含有特定临床相关变体的前瞻性临床样本。在一些有限的情况下,当临床样本,细胞系或生物合成材料不可用时或当真实样本无法完全覆盖生物分析流程时,除生物学样本之外,可以使用含有各种要求类型的已知序列变体(例如,SNV,插入,结构变异,CNV等)的计算机构建的序列标本来评估生物分析流程的性能。申请人可采用分析软件如BAMSurgeon等,编辑满足验证需要的模拟样本或数学模型,对生物分析流程进行验证。但是,这些数据文件应该使用与申报产品相同的预分析和分析方法来生成。应提供每个序列样本中的碱基相关的碱基质量分数,以体现在碱基调取中错误发生的可能性。
2.2准确性
2.2.1总体要求
准确性包括对比检测值与被检测值之间一致性。对于基于NGS测序原理的检测,通过与适当的对比方法比较,如双向测序或其他经过验证的方法,评估申报产品准确性能。
根据检测的性能指标,准确性研究应包括代表性变异和变异类型。研究应考虑与检测适应症相关的临床意义区域、突变频率、跨不同基因片段的变异、基因组难以测序或难以辨识的区域、嵌合体以及任何其他变异类型、区域或被测区域上下限等。
对于每种变异类型以及代表性临床相关变异,加入突变频率考虑,均应计算准确度。对于变异类型,为了确定检测的变异类型以及检测它们的测序区域(不管变异是否具有致病性),可以使用具有代表性的参考物质或具有高置信度的样本进行研究。对于临床相关的变异,准确性计算包含使用基于临床样本的研究数据与临床样本相关的指标。
准确性研究中应含有临床相关变异与检测适应症的临床样本,以确保临床相关序列变异被检测和报告。准确性评估如采用前瞻性临床样本时,收集和处理的方式应与产品预期用途一致。如果前瞻性的临床样本不可用,则可以使用临床相关区域中含有特定变异的冻存临床样本或人类细胞系样本替代或补充研究。
通过阳性符合率(PPA),阴性符合率(NPA)证明试剂准确性。为PPA,NPA设置评价指标,以确保检测满足其预定义的性能范围。通过检测评估的每种类型的变异(如,SNV,插入,结构变异)和测序区域范围(如高度同源,高度多态或其他困难的区域)分别计算PPA,NPA。
表1准确性评估方法

表1注:PPA通过将A(真阴性结果数)除以(A + C)。NPA通过将D(真阴性结果数)除以(D + B)。这些计算不应包含任何无应答或无效答应,无应答或无效答应结果应被单独列出(见表2)。根据适用情况计算每种变体类型以及临床相关变体PPA、NPA。
表2准确性评估方法对比方法
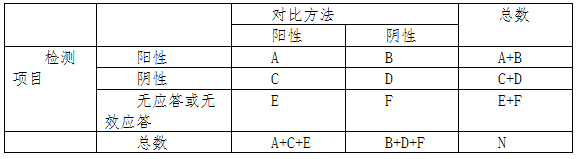
表2注:准确性研究中无应答或无效应答的百分比应该被估计为(E + F)/ N以及95%的双侧置信区间。此外,应评价阴性结果中的无呼叫或无效呼叫E /(A + C + E)和阳性结果中的无呼叫或无效呼叫F /(B + D + F)。申请人应设定无应答或无效应答的最小可接受标准并提供依据。样本总数(N = A + B + C + D + E + F)。申请人应对没应答或无效应答产生原因进行分析,注意区分无呼叫或无效结果与模棱两可结果,如质控正常但结果无法识别的情况等。
2.2.2参考品准确性
各水平、各突变位点的阳性参考品均应按要求检出阳性,考虑到浓度梯度的不同,应对各水平阳性参考品设置相应检出要求;阴性参考品在各个引物探针组合的检测条件下均应检出为阴性。
2.3检测限
明确可接受的最低检测限,并明确无效检测或无应答检测结果可接受标准。为预期用途中包含的每种变异类型建立LoD。如果检测人工混合的样本(如嵌合样本),需要考虑不同的等位基因比率,确定检测限。
试剂LOD的研究中应在不同的常规临床实验室条件和确定的样本类型下进行。通常,LOD值被确立为具有至少95%的阳性检出率和可接受水平的无效的或未检测到的检测水平。当不同的变异类型可能具有不同的LoD时,需要计算不同的序列被测区域范围中的每个变异类型的LoD。NGS检测方法可以同时检测多种类型突变基因,因此灵敏度的设置应根据不同突变基因类型及判读方式进行验证。
2.4空白限(检测基线)
应确认不会对报告区域的质量分数或覆盖率产生负面影响。应包含具有代表性的基因组区域,变异类型和序列背景进行验证研究。设置空白检测限检测标准,设定评价方案及方法。
没有探针采集的区域可以整理并列表展示。采用已知特定区域无突变(变异)的阴性参考品进行重复的检测,发现假阳性时背景噪音。生信对于空白限,需给出有效深度的下限。当数据低于这个值时,视为该位点数据为噪音。
2.5分析特异性
分析特异性是评估产品仅可检测到预期待测变异的能力。根据预期用途和产品设计,一些潜在的内源性或外源性物质干扰和交叉反应或交叉污染可能会对产品检测性能产生影响。
交叉反应(如同源区域,假基因和其他类型的交叉反应序列)可能导致错误检测,从而产生假阳性结果。患者标本的交叉污染可能将其他不正常的序列引入到检测中,从而导致假阳性或假阴性结果。因此,应选择产品预期用途所覆盖样本或样本类型以及DNA提取方法中相关的干扰物质开展研究。同时,应对已知交叉反应的等位基因和同源区域进行评估。此外,需要评估患者样本之间的携带或交叉污染。
2.6精密度
精密度研究主要是指使用相同的样本(包括检测临界值附近的样本)在各种特定条件下进行检测(如不同操作员,不同操作条件,不同检测天数,不同仪器等),并考虑了检测中主要的变异来源。申请人应评估变异和野生型基因的精密度,其中应分别报告不同检测区域和变异类型的检测值。申请人应使用客观证据和有效的统计方法来验证这些指标设定标准。
对可能导致检测结果多样性的主要因素进行评价,包括但不限于检测多个样本,不同检测批间、不同适用机型、试剂批次、检测天数和操作员。
此外,申请人应考虑外部因素相同的情况下,应进行申报试剂在相同或相似被测物的重复性检测以评价检测结果的变异程度。申请人需对每个检测条件和检测区域下每个变异类型精密度分别进行报告,还应报告没有应答或无效应答的百分比。
2.7体细胞与胚系突变鉴别研究(如适用)
在对肿瘤样本进行检测的同时对该患者正常配对样本(正常癌旁组织或外周血白细胞)进行检测,根据配对样本与癌组织样本中鉴定出的突变信息进行鉴别筛选;在患者正常组织无法获得的情况下,或者配对的正常对照测序覆盖度低于质控要求时,申请人应建立一个混合的FFPE的核酸 正常对照用来进行突变比较分析;应确认样本中特有的基因多态性,并明确混合后的每个多态性位点的预期频率。
申请人是否使用配对样本对体细胞突变和胚系突变进行鉴别,但都应遵循保证准确检测的原则。仅对癌症组织进行检测,当无配对样本时,需实验室建立一系列的标准来对体细胞突变和胚系突变进行鉴别。建立主要过滤标准和利用现有的人群数据库(dbSNP,1000G,实验室内部自建等)已标注的胚系突变信息进行过滤,但需要注意的是这些数据库所包含的胚系突变信息可能不全或者有错误之处。因此在无配对样本时,实验室需要对建立的鉴定标准进行验证,确保准确鉴别体细胞突变和胚系突变。
2.8批次互通性(如适用)
NGS的检测通常包括试剂,消耗品,仪器和软件。各部分相对独立,申请人需对各批次之间是否互通进行研究。
2.9软件研究(如适用)
根据申报产品预期用途,可能存在一些软件产品不包含在申报产品组成成分中,但生物信息分析过程中需要用到该软件,则该软件被视为检测系统一部分,申请人应提供该部分软件相关适用性研究资料。
2.10其他
评估检测局限性时,申请人应采用特殊样本,如大于特定大小的插入或缺失或重排,并确定检测无法以预期的准确度和精确度检测到的序列变化类型。如果这些区域是申报产品检测预期用途的一部分,则需要验证高度同源,高度多态或其他困难区域的变异的检测性能。如果被检测的基因组区域的一部分难以测序并且不能达到性能阈值,则应该将其报告为检测局限性。如适用,申请人应记录申报产品不会报告的检测类型。
在设计和验证过程中,申请人应记录所有检测失败情况并分析原因。例如,由于未能满足其一个或多个检测运行质量指标等。不符合质量标准的检测区域不应报告变异阳性结果。由于未能达到检测运行质量标准而未受到检测的区域,则应如实报告。
申报产品上市后,通过上市后数据收集和分析或药物标签中说明明确具有伴随诊断用途的基因,在不改变原有反应体系和检测方式等情况,申请人可通过申请变更其临床用途。
附表1 参数描述列表
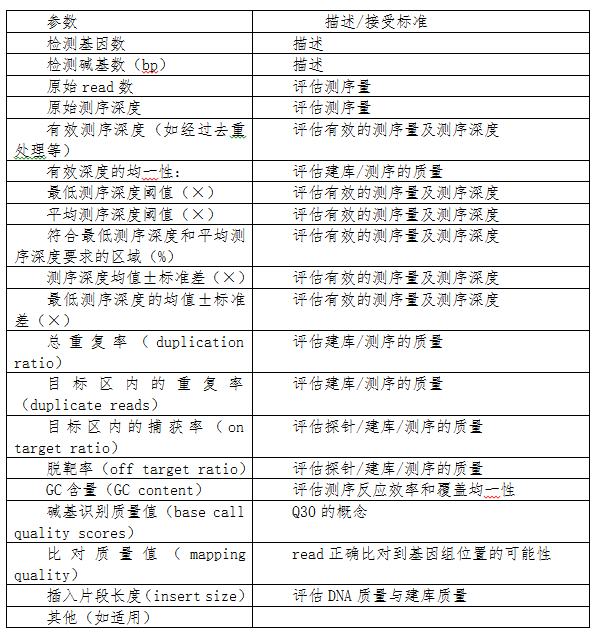
注:检测基因数: 产品能够检测的基因个数。
检测碱基数(bp): 产品能够覆盖的总区域范围,以碱基个数为单位。
原始read数: 测序下机数据总read数。
原始测序深度: 未去除PCR重复等的平均深度。
有效测序深度(如经过去重处理等): 去除PCR重复等后的平均深度。
有效深度的均一性: 大于预设定的有效测序深度阈值的覆盖度。
最低测序深度阈值(×): 满足后续分析要求的各区域内的最低位点深度。
平均测序深度阈值(×): 满足后续分析要求的全区域内的最低平均深度。
符合最低测序深度和平均测序深度要求的区域(%): 最低测序深度和平均测序深度均大于阈值的区域数与区域总数的比值。
测序深度均值±标准差(×):测序深度均值±标准差指某一批次所有检测样本的测序深度均值±标准差;
最低测序深度的均值±标准差(×): 指某一批次所有检测样本的最低测序深度的均值±标准差。
总重复率(duplication ratio): 重复read数与原始read数的比值。
目标区内的重复率(duplicate reads): 目标区域内的重复read数与总目标区域read数的比值。
目标区内的捕获率(on target ratio): 目标区域的read数与原始read数的比值。
脱靶率(off target ratio): 非目标区域的read数与原始read数的比值。
GC含量(GC content): 在测序所得的所有碱基中,GC两种碱基数与所有碱基数的比值
碱基识别质量值(base call quality scores): 碱基质量值是衡量测序质量的重要指标,质量值(Q)越高代表碱基被测错的概率(P)越小,其计算公式为Q=-10 logP;质量值是Q30,则错误识别的概率是0.1%,即错误率0.1%,或者正确率是99.9%。
比对质量值(mapping quality): read比对到参考序列上这个位置的可靠程度,用错误比对到该位置的概率值来描述,MAPQ=-10 logP。
插入片段长度(insert size): 通过检测双端序列在基因组上的起止位置,可以得到插入片段的实际长度,决定了测序的长度,是信息分析的重要参数。
四、参考文献
1.李金明等.高通量测序技术,科学出版社 2018
2.王忻琨. 新一代测序数据分析 科学出版社 2018.2
3.Stuart M.Brown.第二代测序信息处理 科学出版社 2017.1
4.步宏、叶丰等,临床分子病理NGS 100问简明问答(第一版)
5.中国食品药品检定研究院,第二代测序技术检测试剂质量评价通用技术指导原则
6. EVALUATION OF AUTOMATIC CLASS III DESIGNATION FOR MSK-IMPACT (Integrated Mutation Profiling of Actionable Cancer Targets)
7. the Association for Molecular Pathology, American Society of Clinical Oncology,and College of American Pathologists Standards and Guidelines for the Interpretation and Reporting of Sequence Variants in Cancer The Journal of Molecular Diagnostics, Vol. 19, No. 1, January 2017
8.Verification and Validation of Multiplex Nucleic Acid Assays; Approved Guideline. Clinical and Laboratory Standards Institute. NCCLS, MM17-A, Vol.28 No.9, ISBN 1-56238-661-1。
9.Guidelines for Diagnostic Next-Generation Sequencing. European Journal of Human Genetics, 2015, 24(1):1584-1589。
10.ACMG Clinical Laboratory Standards for Next-Generation Sequencing. Genetics in Medicine, 2013, 15(9)。
11.Ewing AD, Houlahan KE, Hu Y, Ellrott K, Caloian C, Yamaguchi TN, Bare JC, P'ng C, Waggott D, Sabelnykova VY et al: Combining tumor genome simulation with crowdsourcing to benchmark somatic single-nucleotide-variant detection. Nature methods 2015, 12(7):623-630.
12.FDA.Considerations for Design,Development, and Analytical Validation of Next Generation Sequencing (NGS) – Based In Vitro Diagnostics (IVDs) Intended to Aid in the Diagnosis of Suspected Germline Diseases13.FDA.use of public human genetic variant databases to support clinical validity for genetic and genomic-based in vitro diagnostics, Document issued on April 13, 2018.
14. FoundationFocus™ CDxBRCA Technical Information Summary
15.中国肿瘤驱动基因分析联盟(CAGC) 中国临床肿瘤学会(CSCO) 二代测序(NGS)技术应用于临床肿瘤精准医学诊断的共识第一版(试行)2016.04.23
16.中国临床肿瘤学会肿瘤标志物专家委员会 中国肿瘤驱动基因分析联盟二代测序技术在肿瘤精准医学诊断中的应用专家共识.中华医学杂志 98(26)2018.7.10